Welcome!

Hi! I am a Ph.D. candidate in the department of Electrical and Computer Engineering (ECE) at University of Wisconsin-Madison, advised by Prof. Dimitris Papailiopoulos and Prof. Kangwook Lee. I received my M.S. in 2020 from Seoul National University, where I was advised by Prof. Jungwoo Lee and learned about communication systems. I also received my B.S. in ECE from Seoul National University. I am a recipient of the Korean Government Scholarship Program for Study Overseas.
I am open to ML research, applied scientist, and ML engineering roles in LLMs, post-training, evaluation, and reasoning.
Research Interest
My research centers on improving the generalization and reasoning capabilities of LLMs and foundation models. Key areas include:
- Generalization beyond training distributions: compositional, length-based, and easy-to-hard transfer
- Algorithmic, mathematical, and abstract reasoning in LLMs
- Leveraging self-improvement frameworks, post-training optimization, RLVR, chain-of-thought prompting, and evaluation pipelines to enhance performance, robustness, and adaptability
Recent News
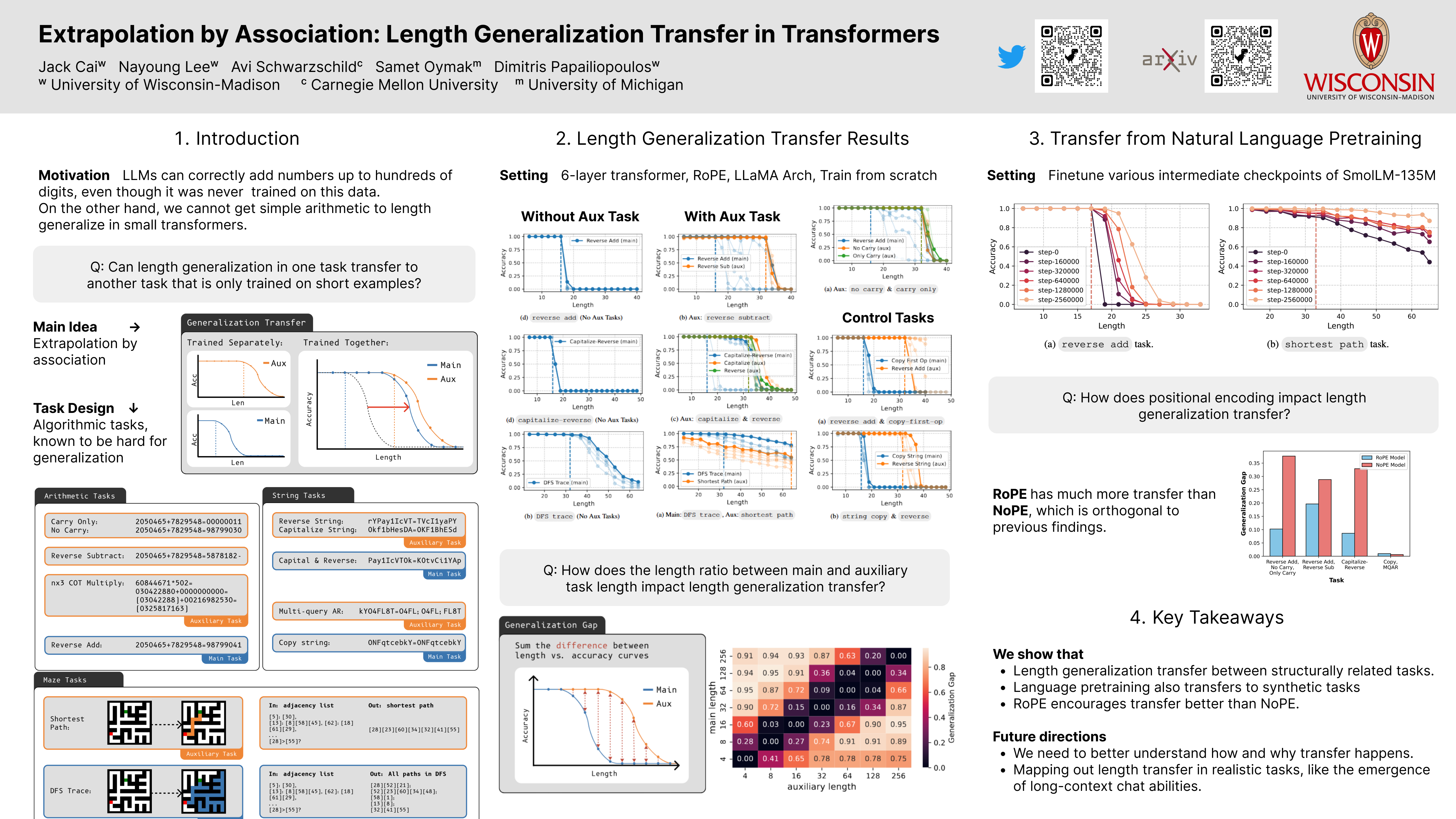
- (Sep. 2025) Our paper Extrapolation by Association: Length Generalization Transfer in Transformers is accepted at Neurips 2025 (Spotlight)! - Paper | Poster
- (May. 2025) Excited to start an internship at Amazon AWS as an Applied Scientist Intern! See you in NYC!
- (May. 2025) Our paper Self-Improving Transformers Overcome Easy-to-Hard and Length Generalization Challenges is accepted at ICML 2025!
- (May. 2024) Our paper Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks is accepted at ICML 2024!
- (Jan. 2024) Our paper Teaching Arithmetic to Small Transformers is accepted at ICLR 2024! - Paper | Poster
- (Aug. 2023) Gave a Short Talk at the Simons Institute LLM workshop! - Video | Slides
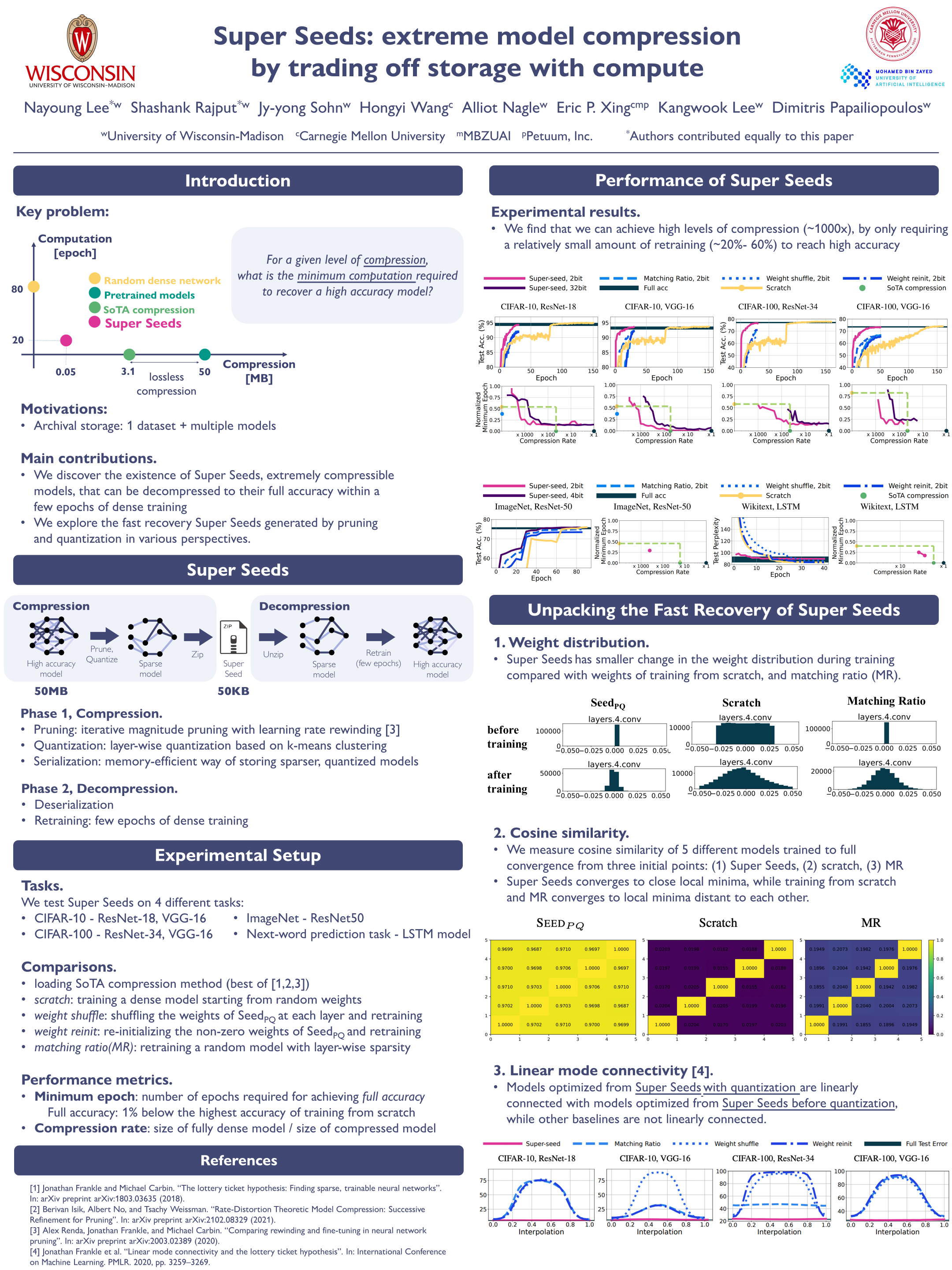
- (Jun. 2022) Our paper Super Seeds: extreme model compression by trading off storage with computation is accepted at ICML 2022 UpML Workshop (Oral Spotlight)! - Paper | Poster
{kind=link}
{kind=link}
Selected Publications
-
Extrapolation by Association: Length Generalization Transfer in Transformers, Neurips 2025 (Spotlight)
Z. Cai, N. Lee, A. Schwarzschild, S. Oymak, D. Papailiopoulos -
Self-Improving Transformers Overcome Easy-to-Hard and Length Generalization Challenges, ICML 2025
N. Lee, Z. Cai, A. Schwarzschild, K. Lee, D. Papailiopoulos -
Can Mamba Learn How to Learn? A Comparative Study on In-Context Learning Tasks, ICML 2024
J. Park, J. Park, Z. Xiong, N. Lee, J. Cho, S. Oymak, K. Lee, D. Papailiopoulos -
Teaching Arithmetic to Small Transformers, ICLR 2024
N. Lee, K. Sreenivasan, J. D. Lee, K. Lee, D. Papailiopoulos
-
Super Seeds: extreme model compression by trading off storage with computation, ICML 2022 Workshop (oral spotlight)
N. Lee, S. Rajput, J. Sohn, H. Wang, A. Nagle, E. Xing, K. Lee, D. Papailiopoulos
Education
Ph.D. Candidate in Electrical and Computer Engineering, University of Wisconsin–Madison (Sep. 2020 – May 2026, expected)
- Advisors: Prof. Dimitris Papailiopoulos & Prof. Kangwook Lee
- Research area: LLM post-training, evaluation, reasoning, and generalization
M.S. in Electrical and Computer Engineering, Seoul National University (Mar. 2018 – Aug. 2020)
- Advisor: Prof. Jungwoo Lee
- Research area: Channel estimation, non-orthogonal multiple access
- Thesis: Channel Estimation Using Deep Complex Networks in Massive MIMO-OFDM System
B.S. in Electrical and Computer Engineering, Seoul National University (Mar. 2014 – Feb. 2018)
- Summa Cum Laude
Work Experience
Amazon AWS (2025.05 - 2025.08)
- Applied Scientist Intern
- Mentor: Dr. Dionysis Manousakas
- Project: Learning to Improve Without Labels: Diversity as the Key to LLM Self-Improvement
- Built self-improving LLM post-training pipelines using model-generated data and analyzed diversity collapse and filtering strategies for performance improvement.
Nanyang Technological University, SNU (2017.06 - 2017.08)
- Undergraduate Research Intern
- Mentor: Prof. Junsong Yuan
- Projects: Hand Gesture Recognition Task Using Deep Learning Based on Google Soli
- Improved hand gesture recognition accuracy and implemented a low-latency online recognition system.
Teaching Experience
Graduate Teaching Assistant
- (UW-Madison CS/ECE 561) Probability and Information Theory in Machine Learning, 2022 Fall
- (UW-Madison CS/ECE/ME 532) Matrix Methods in Machine Learning, 2021 Fall
- (SNU) Information Theory, 2019-1
- (SNU) Introduction to Communications, 2018-2
Undergraduate Teaching Assistant
- (SNU) Foundation of Physics 1, 2015-1, 2016-1,2017-1
- (SNU) Foundation of Physics 2, 2015-2, 2016-2, 2017-2
Talks
- (02.24.2025) Talk at the FLaNN Seminars
- (09.11.2023) Talk at the IFDS Ideas Forum
-
(08.18.2023) Short Talk at the Simons Institute LLM Workshop - Video Slides